Failover automático e transparente do
Postgres com pgpool
Tenho trabalhado muito com o pgpool recentemente e queria documentar
meus experimentos, caso sejam úteis para outros.
Neste post, documentarei passo a passo como instalar postgres/pgpool e como configurar
o pgpool para automatizar o failover. Em seguida, instalarei uma interface
gráfica em cima do pgpool .
Introdução
Este post tem a intenção de ser um
material de aprendizado, ele lista passo a passo como instalar
postgres/pgpool/repmgr. Como tudo pode ser feito na linha de comando, mais
tarde expandirei essa configuração para fazer testes automatizados do watchdog pgpool.
Observe que na minha empresa atual eu implantei postgres e pgpool como imagens
docker, em um docker swarm ou diretamente nos servidores (ou seja, usando docker
run para iniciar os contêineres). Tudo isso está no repositório do github
https://github.com/saule1508/pgcluster .
Se você começar uma jornada de aprendizado
com pgpool e postgres, usar docker pode ser de grande ajuda porque torna a experimentação
e o teste muito fáceis (você pode começar rapidamente do zero).
Darei mais ênfase aos conceitos ou configurações do pgpool que achei
difíceis de entender (às vezes porque são mal documentados). Para postgres e
repmgr e listarei essencialmente todos os passos necessários para configurá-lo,
mas é obviamente muito recomendado ler os respectivos documentos.
O resultado final é uma configuração
composta de 3 servidores Centos 7.6: um banco de dados primário e dois bancos
de dados stand-by, com um pgpool em cada nó tornado de alta disponibilidade com
o modo watch-dog do pgpool. Eu uso repmgr ( https://repmgr.org/ ), não para automatizar o
failover, mas porque ele traz scripts bem testados sobre a replicação do
postgres. NB: Estou usando libvirt para provisionar a VM (eu
provisiono um servidor e depois o clonei), mas você pode usar vagrant, virtual
box, VMWare ou provisionar os convidados centos manualmente. Se você tiver um
host Linux disponível, então sugiro usar libvirt, eu documentei aqui uma
maneira de provisionar um convidado centos a partir da linha de comando em
alguns minutos: Centos guest VM com cloud-init , isso é
simplesmente ótimo.
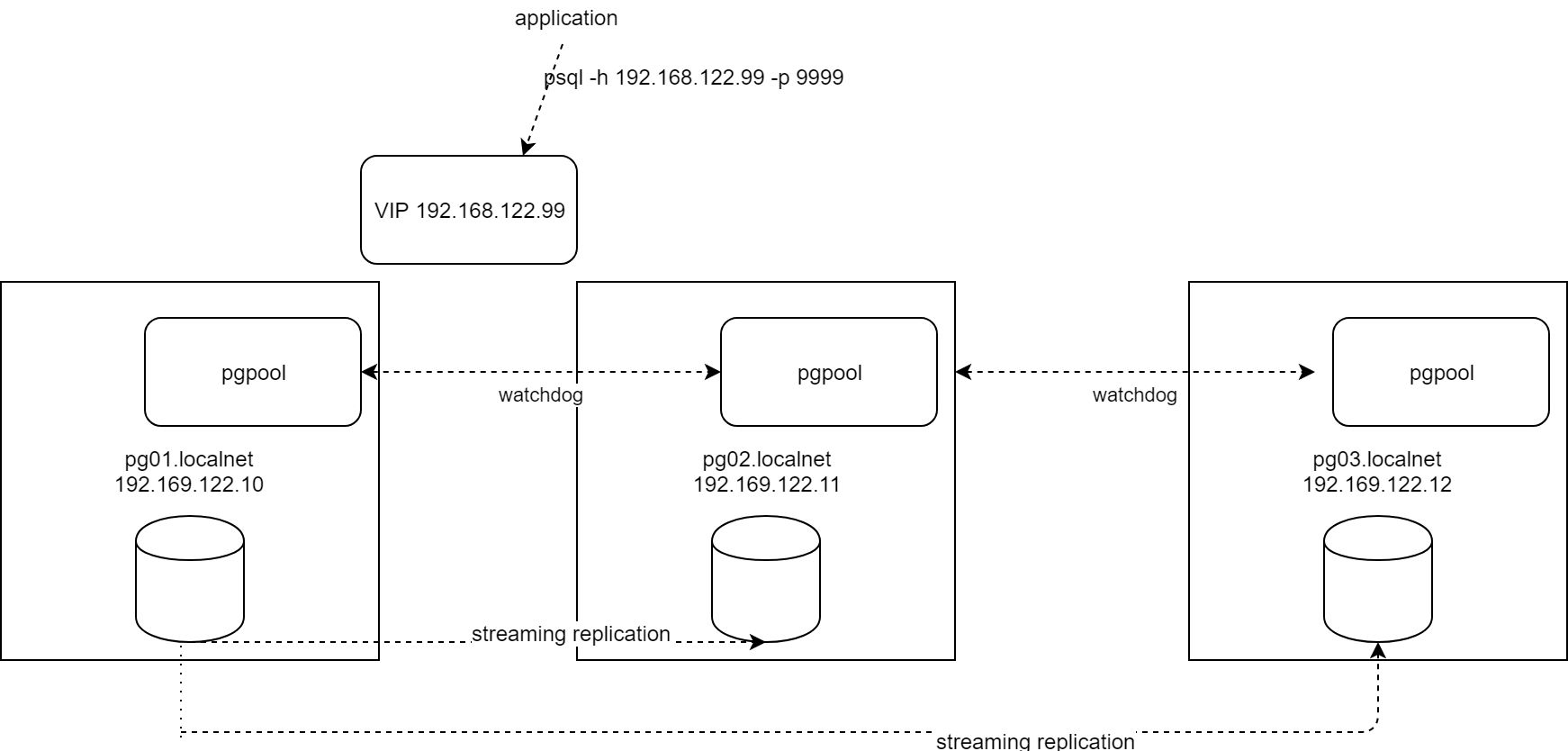
O resultado final será semelhante a este:
diagrama
interface gráfica
pgpool: alguns fatos
Antes de construir a configuração, aqui estão algumas considerações
sobre o Pgpool. O Pgpool é difícil e aprender porque ele pode fazer muitas
coisas e a documentação é esmagadora e nem sempre clara. Existem 3 funções
principais que são úteis, as outras são mais esotéricas ou por razões
históricas (como cache de resultados de consulta, replicação mestre-mestre,…).
O Pgpool tem uma boa comunidade e, uma vez que o conhecemos, gostamos dele
Cache de conexão
Se você pensar sobre o pool de conexão tradicional no mundo Java, onde o
webcontainer gerencia o pool de conexão e os threads Java pegam emprestado uma
conexão do pool para o momento de uma transação, então você ficará confuso com
o Pgpool. O Pgpool faz cache de conexão. Quando o aplicativo se conecta ao
Pgpool, o Pgpool usa um de seus processos filhos, então cria uma conexão com o
postgres e associa a conexão do postgres ao processo filho.
Quando o aplicativo se desconecta do pgpool, a conexão do postgres é limpa
(para liberar bloqueios, por exemplo) e é mantida aberta, para que permaneça no
cache para a próxima vez.
Se você tiver aplicativos modernos usando
pool de conexão e tiver muitos bancos de dados ou nomes de usuário diferentes,
o cache de conexão do pgpool pode não ser interessante e pode ser desabilitado
(parâmetro connection_cache='off' ) Failover automatizado e (principalmente) transparente
O Postgres tem um forte mecanismo de replicação (hot standby) no qual um
banco de dados primário transmite seus logs de transação (wal na terminologia
do postgres, write-ahead-logs) e um ou mais bancos de dados standby recebem
esses write-ahead-log e os aplicam continuamente para que todas as alterações feitas
no primário sejam replicadas nos standbys. O banco de dados primário é aberto
para leitura e gravação, os bancos de dados standby são abertos somente para
leitura. Mas o postgres não oferece nenhuma maneira automatizada de promover um
banco de dados standby em caso de falha do primário. Além disso, se um banco de
dados standby for promovido manualmente e se tornar o novo banco de dados
read-write, todos os aplicativos conectados ao banco de dados devem agora ser
informados de que devem se conectar a uma nova instância.
O pgpool resolve esses problemas, ele é usado em cima dos bancos de
dados postgres, agindo como um proxy, ele usa os seguintes mecanismos para
detectar uma falha e disparar um failover:
health checks: o pgpool se conecta
(com o usuário health_check_user )
regularmente (param health_check_period )
aos bancos de dados e, portanto, fica ciente quando um primário (ou um standby)
falha. Após um período de nova tentativa ( health_check_retry_interval e health_check_retries ), ele acionará um failover,
o que significa concretamente chamar um script com vários argumentos.
Alternativamente, ele pode usar o parâmetro failover_on_backend_error .
Este parâmetro deve estar desativado se você usar a verificação de integridade.
O que o erro failover_on_backend significa é que quando o Pgpool recebe um erro
em uma das conexões, ele imediatamente acionará um failover. Portanto, não há
nova tentativa. Além disso, se não houver atividade, a falha não será detectada
e o failover não ocorrerá.
O failover transparente é obtido porque os clientes estão se conectando
ao pgpool e não diretamente ao postgres: se um failover acontecer, o pgpool
saberá que o banco de dados primário foi alterado e destruirá e recriará todas
as conexões ao postgres sem nenhuma configuração necessária no lado do cliente.
Claro que não é completamente transparente, qualquer instrução (consulta ou
atualização) que estava sendo executada retornará um erro.
Mas se o pgpool for um proxy entre os aplicativos e o postgres, uma
falha do próprio pgpool resultaria em perda de disponibilidade. Em outras
palavras, o próprio pgpool se tornou o único ponto de falha e, claro, tem um
mecanismo muito bom que o torna HA: o modo watchdog
modo watchdog pgpool
watchdog adiciona alta
disponibilidade coordenando múltiplos nós pgpool (um liderado eleito via
consenso). O líder adquire o VIP (a aquisição do VIP é feita via script usando
ip e arp)
Os nós do pgpool se comunicam via porta tcp 9000 (comando ADD_NODE, etc.)
watchdog usa um mecanismo de heartbeat (opcionalmente, pode usar um mecanismo
de consulta): um “processo lifecheck” envia e recebe dados via UDP (porta 9694)
para verificar a disponibilidade de outros nós
protocolo de gerenciamento pgpool
O pcp expõe sua função através do pcp (protocolo de controle pgpool) na
porta tcp 9898. Isso requer um usuário (escolha postgres) e uma senha (a
combinação deve ser armazenada em um arquivo /home/postgres/.pcppass), para que
o usuário linux postgres possa usar pcp_attach_node, pcp_recovery_node, etc…
1. Crie o primeiro servidor com centos 7, postgres, repmgr e pgpool
A instalação do guest centos 7 é
descrita no link http://saule1508.github.io/libvirt-centos-cloud-image .
Ele precisa de um sistema de arquivos /u01 para o banco de dados (o BD
estará em /u01/pg11/data), um sistema de arquivos /u02 para os logs de gravação
antecipada arquivados (wal) e os backups (/u02/archive e /u02/backup). Eu crio
um usuário postgres com uid 50010 (id arbitrário, não importa, mas é melhor ter
o mesmo id em todos os servidores). O usuário deve ser criado antes que o rpm
seja instalado.
1.2 PostgreSQL
# as user root
MAJORVER=11
MINORVER=2
yum update -y
# install some useful packages
yum install -y epel-release libxslt sudo openssh-server
openssh-clients jq passwd rsync iproute python-setuptools hostname inotify-tools
yum-utils which sudo
vi
firewalld
# create user postgres before
installing postgres rpm, because I want to fix the uid
useradd -u 50010 postgres
# set a password
passwd postgres
# So that postgres can become root
without password, I add it in sudoers
echo "postgres ALL=(ALL)
NOPASSWD:ALL" >
/etc/sudoers.d/postgres
# install postgres release rpm, this
will add a file /etc/yum.repos.d/pgdg-11-centos.repo
yum install -y
https://download.postgresql.org/pub/repos/yum/${MAJORVER}/redhat/rhel-7-x86_64/pgdg-centos${MAJORVER}-${MAJORVER}-${MINORVER}.noarch.rpm
# with the repo added (repo is called
pgdg11), ww can install postgres
# NB: postgres is also available from
Centos base repos, but we want the latest version (11)
yum install -y postgresql${MAJORVER}-${MAJORVER}.${MINORVER} postgresql${MAJORVER}-server-${MAJORVER}.${MINORVER} postgresql${MAJORVER}-contrib-${MAJORVER}.${MINORVER}
# verify
yum list installed postgresql*
Quero armazenar o banco de dados postgres em /u01/pg11/data (local não
padrão), quero ter o wal arquivado em /u02/archive e o backup em /u02/backup
mkdir -p /u01/pg${MAJORVER}/data /u02/archive /u02/backup
chown postgres:postgres /u01/pg${MAJORVER}/data /u02/archive
/u02/backup
chmod 700 /u01/pg${MAJORVER}/data /u02/archive
A variável de ambiente PGDATA é importante: ela aponta para o local do
banco de dados. Precisamos alterá-la do rpm padrão (que é /var/lib/pgsql/11/data)
para o novo local /u01/pg11/data.
export PGDATA=/u01/pg${MAJORVER}/data
# add the binaries in the path of all
users
echo "export PATH=\$PATH:/usr/pgsql-${MAJORVER}/bin" > /etc/profile.d/postgres.sh
# source /etc/profile in bashrc of user
postgres, make sure that PGDATA is defined and also PGVER so that we
# can use PGVER in later scripts
echo "[ -f /etc/profile ] &&
source /etc/profile" >>
/home/postgres/.bashrc
echo "export PGDATA=/u01/pg${MAJORVER}/data" >>
/home/postgres/.bashrc
echo "export PGVER=${MAJORVER}" >>
/home/postgres/.bashrc
Precisamos de um arquivo de unidade
systemd para o postgres, para que ele seja iniciado automaticamente quando
inicializamos o servidor (veja https://www.postgresql.org/docs/11/server-start.html )
cat <<EOF >
/etc/systemd/system/postgresql.service
[Unit]
Description=PostgreSQL database server
Documentation=man:postgres(1)
[Service]
Type=notify
User=postgres
ExecStart=/usr/pgsql-11/bin/postgres -D
/u01/pg11/data
ExecReload=/bin/kill -HUP $MAINPID
KillMode=mixed
KillSignal=SIGINT
TimeoutSec=0
[Install]
WantedBy=multi-user.target
EOF
habilite a unidade, mas não a inicie ainda
sudo systemctl enable postgresql
Agora podemos inicializar o banco de dados, como usuário postgres
su - postgres
# check that PGDATA and the PATH are
correct
echo $PGDATA
echo $PATH
pg_ctl -D ${PGDATA} initdb -o "--auth=trust --encoding=UTF8
--locale='en_US.UTF8'"
Os parâmetros de configuração do postgres estão em $PGDATA/postgres.conf,
prefiro não alterar esse arquivo, mas incluir um arquivo adicional do diretório
config.d e substituir alguns dos parâmetros padrões. Eu adiciono a linha
“include_dir='conf.d'” no final do postgresql.conf e, em seguida, adiciono configurações
personalizadas em conf.d
# as user postgres
mkdir $PGDATA/conf.d
echo "include_dir = 'conf.d'" >> $PGDATA/postgresql.conf
# now let's add some config in this
conf.d directory
cat <<EOF > $PGDATA/conf.d/custom.conf
log_destination = 'syslog,csvlog'
logging_collector = on
# better to put the logs outside PGDATA
so they are not included in the base_backup
log_directory = '/var/log/postgres'
log_filename =
'postgresql-%Y-%m-%d.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
# These are relevant when logging to
syslog (if wanted, change log_destination to 'csvlog,syslog')
log_min_duration_statement=-1
log_duration = on
log_line_prefix='%m %c %u - '
log_statement = 'all'
log_connections = on
log_disconnections = on
log_checkpoints = on
log_timezone = 'Europe/Brussels'
# up to 30% of RAM. Too high is not
good.
shared_buffers = 512MB
#checkpoint at least every 15min
checkpoint_timeout = 15min
#if possible, be more restrictive
listen_addresses='*'
#for standby
max_replication_slots = 5
archive_mode = on
archive_command =
'/opt/postgres/scripts/archive.sh %p %f'
# archive_command = '/bin/true'
wal_level = replica
max_wal_senders = 5
hot_standby = on
hot_standby_feedback = on
# for pg_rewind
wal_log_hints=true
EOF
Eu prefiro colocar os logs fora do PGDATA, caso contrário um backup pode
ficar muito grande só por causa dos logs. Então precisamos criar o diretório
sudo mkdir /var/log/postgres
sudo chown postgres:postgres
/var/log/postgres
Como você pode ver, eu uso o script /opt/postgres/scripts/archive.sh
como comando de arquivamento, isso precisa ser criado
sudo mkdir -p
/opt/postgres/scripts
sudo chown -R postgres:postgres
/opt/postgres
conteúdo do script /opt/postgres/scripts/archive.sh
#!/bin/bash
LOGFILE=/var/log/postgres/archive.log
if [ ! -f $LOGFILE ] ; then
touch $LOGFILE
fi
echo "archiving $1 to /u02/archive/$2"
cp $1 /u02/archive/$2
exit $?
certifique-se de que é executável
chmod +x /opt/postgres/scripts/archive.sh
⚠️: Quando o modo de arquivamento
estiver ativado, você deve limpar o diretório onde os wals arquivados são
copiados. Normalmente, por meio de um script de backup que faz um backup e, em
seguida, remove os wals arquivados mais antigos do que o backup
Agora vamos criar um banco de dados e um usuário
sudo systemctl start postgresql
# verify
sudo systemctl status postgresql
psql -U postgres postgres
no prompt do psql, crie um banco de dados (meu banco de dados é chamado
critlib) e saia
create database critlib encoding
'UTF8' LC_COLLATE='en_US.UTF8';
\q
agora reconecte-se ao banco de dados recém-criado e crie dois usuários
(cl_owner e cl_user)
psql -U postgres critlib
create user cl_owner nosuperuser
nocreatedb login password 'cl_owner';
create schema cl_owner authorization
cl_owner;
create user cl_user nosuperuser
nocreatedb login password 'cl_user';
grant usage on schema cl_owner to
cl_user;
alter default privileges in schema
cl_owner grant select,insert,update,delete on tables to cl_user;
alter role cl_user set search_path to
"$user",cl_owner,public;
\q
Vamos abrir a porta 5432 do firewall
# as root
firewall-cmd --add-port 5432/tcp --permanent
systemctl restart firewalld
Antes de clonar o servidor (precisamos de 3 servidores), instalarei os
pacotes repmgr e pgpool. Depois disso, podemos clonar o servidor (é uma VM!),
configurar a replicação de streaming com repmgr e, em seguida, configurar o
pgpool
1.2 repmgr
Repmgr é uma boa ferramenta de código aberto feita pela 2ndquadrant. Não
é obrigatório usá-la e, a princípio, talvez valha a pena configurar a
replicação de streaming usando comandos postgres padrão, para fins de
aprendizado. Mas, de outra forma, vale muito a pena usar repmgr porque ele traz
scripts muito bem testados e documentados. Observe que repmgr também pode ser
usado para automatizar o failover (por meio do processo daemon repmgrd), mas
não queremos isso porque usaremos pgpool.
MAJORVER=11
REPMGRVER=4.2
curl
https://dl.2ndquadrant.com/default/release/get/${MAJORVER}/rpm | bash
yum install -y --enablerepo=2ndquadrant-dl-default-release-pg${MAJORVER} --disablerepo=pgdg${MAJORVER} repmgr${MAJORVER}-${REPMGRVER}
mkdir /var/log/repmgr && chown postgres:postgres
/var/log/repmgr
definir propriedade de /etc/repmgr para postgres
chown -R postgres:postgres /etc/repmgr
1.3 instalar pgpool
Isto é apenas sobre instalar o rpm, a configuração será feita mais
tarde. A configuração tem que ser feita em cada servidor, mas já podemos
instalar o pgpool antes de clonar o servidor. Adicionar o pgpool no Centos é
fácil: instale o rpm de lançamento do pgpool (ele criará um arquivo repo em
/etc/yum.repo.d) e então instale o próprio pgpool via yum.
export PGPOOLMAJOR=4.0
export PGPOOLVER=4.0.3
export PGVER=11
yum install -y http://www.pgpool.net/yum/rpms/${PGPOOLMAJOR}/redhat/rhel-7-x86_64/pgpool-II-release-${PGPOOLMAJOR}-1.noarch.rpm
yum install --disablerepo=pgdg11 --enablerepo=pgpool40 -y pgpool-II-pg11-${PGPOOLVER}
pgpool-II-pg11-extensions-${PGPOOLVER} pgpool-II-pg11-debuginfo-${PGPOOLVER}
``
I prefer to have pgpool running as user
postgres, so I will override the systemd unit file that was installed by the
rpm
```bash
# as user root
mkdir /etc/systemd/system/pgpool.service.d
cat <<EOF >
/etc/systemd/system/pgpool.service.d/override.conf
[Service]
User=postgres
Group=postgres
EOF
Como o pgpool se conecta aos vários servidores postgres via ssh,
adicionei algumas configurações ao cliente ssh para facilitar as conexões ssh
cat <<EOF > /etc/ssh/ssh_config
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
EOF
Como usarei o usuário postgres para iniciar o pgpool, alterarei a
propriedade de /opt/pgpool-II
sudo chown postgres:postgres -R /etc/pgpool-II
Também preciso criar um diretório para o arquivo pid e o arquivo socket
sudo mkdir /var/run/pgpool
sudo chown postgres:postgres
/var/run/pgpool
1.4 Clonar os servidores
Agora que tenho o pg01 pronto, vou cloná-lo para o pg02 e o pg03
Estou usando virsh (KVM) para
gerenciar meus convidados, esses são os comandos que usei para clonar minha VM
(a VM foi criada com este procedimento http://saule1508.github.io/libvirt-centos-cloud-image )
Observação: isso é principalmente para meu próprio registro. Sua maneira
de clonar uma VM pode ser diferente, é claro, ou você pode ter servidores
físicos ou pode usar o Ansible para automatizar o provisionamento...
# on my host
virsh shutdown pg01
sudo mkdir /u01/virt/{pg02,pg03}
sudo chown pierre:pierre
/u01/virt/pg02 /u01/virt/pg03
virt-clone -o pg01 -n pg02 --file /u01/virt/pg02/pg02.qcow2
--file
/u01/virt/pg02/pg02-disk1.qcow2
virt-clone -o pg01 -n pg03 --file
/u01/virt/pg03/pg03.qcow2 --file /u01/virt/pg03/pg03-disk1.qcow2
Agora inicie a VM, entre nela e altere seu endereço IP. Para ter um DNS,
também adiciono uma entrada em /etc/hosts do host KVM
# /etc/hosts of the KVM server, add one
entry per vm so that they can speak to each other via dns
# added
192.168.122.10 pg01.localnet
192.168.122.11 pg02.localnet
192.168.122.13 pg03.localnet
ao fazer isso, é preciso parar e iniciar a rede padrão e reiniciar o
libvirtd
virsh net-destroy default
virsh net-start default
sudo systemctl restart libvirtd
Conecte-se a cada VM via ssh, altere o endereço IP e o nome do host
(hostname-ctl set-hostname)
2. Configurar replicação de streaming com repmgr
Agora tenho 3 centos 7 VM com postgres, repmgr e pgpool instalados. As 3
VM podem resolver os nomes umas das outras via DNS, mas alternativamente
poderíamos colocar 3 entradas no arquivo /etc/hosts em cada VM
|
Hospedar |
Propriedade Intelectual |
|
pg01.localnet |
192.168.122.10 |
|
pg02.localnet |
192.168.122.11 |
|
pg03.localnet |
192.168.122.12 |
Usaremos o repmgr para configurar as 3 instâncias do postgres em uma
configuração primária - standby, onde o pg01 será o primário. O pg01 fará o
streaming de seus logs de gravação antecipada (wal) para o pg02 e o pg03.
Primeiro, queremos configurar chaves ssh para que cada servidor possa se
conectar com o usuário postgres. Em cada servidor, gere um par de chaves ssh
para o usuário postgres e transfira a chave pública para ambos os outros
servidores.
# on pg01 as user postgres. Keep the
default (no passphrase)
ss-keygen -t rsa
ssh-copy-id postgres@pg01.localnet
ssh-copy-id postgres@pg02.localnet
ssh-copy-id postgres@pg03.localnet
Do pg01 postgres o usuário deve ser capaz de se conectar ao pg02 e pg03,
mas também ao pg01 (ele mesmo) via ssh sem uma senha. Isso ocorre porque o
pgpool - em execução nesses servidores - se conectará via ssh a qualquer
servidor postgres para executar alguma operação (promoção de espera,
acompanhamento de espera, recuperação de nó)
faça o mesmo no servidor pg02 e no servidor pg03
2.1 banco de dados primário em pg01
Para a replicação de streaming, usaremos o usuário repmgr com senha
rep123. Vamos criá-lo.
crie o usuário repmgr
# on pg01 as user postgres
psql <<-EOF
create user repmgr with superuser login password 'rep123' ;
alter user repmgr set search_path to repmgr,"\$user",public;
\q
EOF
crie um banco de dados chamado repmgr
# on pg01 as user postgres
psql --command "create database repmgr with owner=repmgr
ENCODING='UTF8' LC_COLLATE='en_US.UTF8';"
Queremos nos conectar ao repmgr sem senha, é para isso que serve o
arquivo oculto pgpass.
# on pg01 as user postgres
echo "*:*:repmgr:repmgr:rep123" >
/home/postgres/.pgpass
echo "*:*:replication:repmgr:rep123" >>
/home/postgres/.pgpass
chmod 600 /home/postgres/.pgpass
scp /home/postgres/.pgpass
pg02.localnet:/home/postgres/.pgpass
scp /home/postgres/.pgpass
pg03.localnet:/home/postgres/.pgpass
Adicionar entradas em $PGDATA/pg_hba.conf para repmgr
# on pg01 as user postgres
cat <<EOF >> $PGDATA/pg_hba.conf
# replication manager
local
replication repmgr trust
host
replication repmgr 127.0.0.1/32 trust
host
replication repmgr 0.0.0.0/0 md5
local
repmgr repmgr trust
host
repmgr repmgr 127.0.0.1/32 trust
host
repmgr repmgr 127.0.0.1/32 trust
host
repmgr repmgr 0.0.0.0/0 md5
host
all all 0.0.0.0/0 md5
EOF
sudo systemctl restart postgresql
crie o arquivo de configuração repmgr
# on pg01 as user postgres
cat <<EOF > /etc/repmgr/11/repmgr.conf
node_id=1
node_name=pg01.localnet
conninfo='host=pg01.localnet
dbname=repmgr user=repmgr password=rep123 connect_timeout=2'
data_directory='/u01/pg11/data'
use_replication_slots=yes
#
event_notification_command='/opt/postgres/scripts/repmgrd_event.sh %n
"%e" %s "%t" "%d" %p %c %a'
reconnect_attempts=10
reconnect_interval=1
restore_command = 'cp /u02/archive/%f
%p'
log_facility=STDERR
failover=manual
monitor_interval_secs=5
pg_bindir='/usr/pgsql-11/bin'
service_start_command = 'sudo systemctl
start postgresql'
service_stop_command = 'sudo systemctl
stop postgresql'
service_restart_command = 'sudo
systemctl restart postgresql'
service_reload_command = 'pg_ctl
reload'
promote_command='repmgr -f
/etc/repmgr/11/repmgr.conf standby promote'
follow_command='repmgr -f
/etc/repmgr/11/repmgr.conf standby follow -W --upstream-node-id=%n'
EOF
Agora registre este banco de dados como sendo o banco de dados primário
# on pg01 as user postgres
repmgr -f /etc/repmgr/11/repmgr.conf -v master register
repmgr mantém informações sobre a topologia do cluster em uma tabela
chamada nodes
psql -U repmgr repmgr -c "select * from
nodes;"
Agora podemos habilitar a unidade systemd postgresql, para que o
postgres seja iniciado na próxima inicialização
# on pg01
sudo systemctl enable postgresql
2.2. Banco de dados standby em pg02
Agora podemos ir para o primeiro standby, pg02, e configurá-lo como um
standby
# on pg02 as user postgres
cat <<EOF > /etc/repmgr/11/repmgr.conf
node_id=2
node_name=pg02.localnet
conninfo='host=pg02.localnet
dbname=repmgr user=repmgr password=rep123 connect_timeout=2'
data_directory='/u01/pg11/data'
use_replication_slots=yes
#
event_notification_command='/opt/postgres/scripts/repmgrd_event.sh %n
"%e" %s "%t" "%d" %p %c %a'
reconnect_attempts=10
reconnect_interval=1
restore_command = 'cp /u02/archive/%f
%p'
log_facility=STDERR
failover=manual
monitor_interval_secs=5
pg_bindir='/usr/pgsql-11/bin'
service_start_command = 'sudo systemctl
start postgresql'
service_stop_command = 'sudo systemctl
stop postgresql'
service_restart_command = 'sudo
systemctl restart postgresql'
service_reload_command = 'pg_ctl
reload'
promote_command='repmgr -f
/etc/repmgr/11/repmgr.conf standby promote'
follow_command='repmgr -f
/etc/repmgr/11/repmgr.conf standby follow -W --upstream-node-id=%n'
EOF
vamos limpar o banco de dados e o wal arquivado
# make sure postgres is not running !
sudo systemctl stop postgresql
# on pg02 as user postgres
rm -rf /u01/pg11/data/*
rm -rf /u02/archive/*
E agora vamos configurar este servidor como um standby
repmgr -h pg01.localnet -U repmgr -d repmgr -D /u01/pg11/data -f
/etc/repmgr/11/repmgr.conf standby clone
sudo systemctl start postgresql
repmgr -f /etc/repmgr/11/repmgr.conf standby
register --force
se não funcionar, verifique se você consegue se conectar a pg01.localnet
(talvez você tenha esquecido o firewall?): psql -h pg01.localnet -U repmgr
repmgr deve funcionar
podemos habilitar a unidade postgresql para que o postgres inicie
automaticamente na próxima reinicialização
sudo systemctl enable postgresql
A tabela de nós agora deve ter dois registros
psql -U repmgr -c "select * from nodes;"
2.3. Banco de dados standby em pg03
Vamos fazer o mesmo no terceiro standby, pg03, e configurá-lo como um
standby
# on pg03 as user postgres
cat <<EOF > /etc/repmgr/11/repmgr.conf
node_id=3
node_name=pg03.localnet
conninfo='host=pg03.localnet
dbname=repmgr user=repmgr password=rep123 connect_timeout=2'
data_directory='/u01/pg11/data'
use_replication_slots=yes
#
event_notification_command='/opt/postgres/scripts/repmgrd_event.sh %n
"%e" %s "%t" "%d" %p %c %a'
reconnect_attempts=10
reconnect_interval=1
restore_command = 'cp /u02/archive/%f
%p'
log_facility=STDERR
failover=manual
monitor_interval_secs=5
pg_bindir='/usr/pgsql-11/bin'
service_start_command = 'sudo systemctl
start postgresql'
service_stop_command = 'sudo systemctl
stop postgresql'
service_restart_command = 'sudo systemctl
restart postgresql'
service_reload_command = 'pg_ctl
reload'
promote_command='repmgr -f
/etc/repmgr/11/repmgr.conf standby promote'
follow_command='repmgr -f
/etc/repmgr/11/repmgr.conf standby follow -W --upstream-node-id=%n'
EOF
vamos limpar o banco de dados e o wal arquivado
# make sure postgres is not running !
sudo systemctl stop postgresql
# on pg03 as user postgres
rm -rf /u01/pg11/data/*
rm -rf /u02/archive/*
E agora vamos configurar este servidor como um standby
repmgr -h pg01.localnet -U repmgr -d repmgr -D /u01/pg11/data -f
/etc/repmgr/11/repmgr.conf standby clone
sudo systemctl start postgresql
repmgr -f /etc/repmgr/11/repmgr.conf standby
register --force
podemos habilitar a unidade postgresql para que o postgres inicie
automaticamente na próxima reinicialização
sudo systemctl enable postgresql
Verifique os nós das tabelas repmgr
psql -U repmgr repmgr -c "select * from
nodes;"
2.4. Teste de replicação de streaming
# on pg01 as user postgres
# check the nodes table, it contains
meta-data for repmgr
psql -U repmgr repmgr -c "select * from
nodes;"
# create a test table
psql -U repmgr repmgr -c "create table
test(c1 int, message varchar(120)); insert into test values(1,'this is a
test');"
# check on pg02 if I can see the table
and if it is read-only
psql -h pg02.localnet -U repmgr repmgr <<EOF
select * from test;
drop table test;
EOF
# it will say: ERROR: cannot execute DROP TABLE in a read-only
transaction
# check on pg03 if I can see the table
and if it is read-only
psql -h pg03.localnet -U repmgr repmgr <<EOF
select * from test;
drop table test;
EOF
# drop the table on pg01
psql -U repmgr repmgr -c "drop table
test;"
Experimente um pouco com operações básicas: failover, switch-over,
seguir um novo mestre, reingressar em um primário com falha, etc. O repmgr tem
scripts para tudo isso.
3. pgpool
Agora é hora de configurar o pgpool em nossos 3 servidores. O pgpool
pode ser usado como um cache de conexão, mas - mais importante - ele é usado
para automatizar o failover do postgres e torná-lo (quase) transparente para os
aplicativos clientes.
Lembre-se de que o postgres se torna HA (Alta Disponibilidade) por meio
da replicação de streaming e que o pgpool se torna HA por meio de um IP Virtual
(VIP) gerenciado pelo modo watchdog.
A linha a seguir deve ser adicionada à configuração do postgres (não
tenho certeza do porquê e se ainda é necessária)
echo "pgpool.pg_ctl='/usr/pgsql-11/bin/pg_ctl'" >> $PGDATA/conf.d/custom.conf
3.1. Arquivos pgool_hba e pool_passwd
semelhante ao mecanismo de autenticação baseado em host do postgres
(pg_hba), o pgpool tem um arquivo pool_hba.conf.
cat <<EOF > /etc/pgpool-II/pool_hba.conf
local
all all trust
# IPv4 local connections:
host
all all 0.0.0.0/0 md5
EOF
scp /etc/pgpool-II/pool_hba.conf
postgres@pg02.localnet:/etc/pgpool-II/
scp /etc/pgpool-II/pool_hba.conf
postgres@pg03.localnet:/etc/pgpool-II/
Como uso md5, preciso ter o arquivo
pool_passwd contendo a senha com hash md5 http://www.pgpool.net/docs/latest/en/html/runtime-config-connection.html#GUC-POOL-PASSWD
# first dump the info into a temp file
psql -c "select rolname,rolpassword from
pg_authid;" > /tmp/users.tmp
touch /etc/pgpool-II/pool_passwd
# then go through the file to
remove/add the entry in pool_passwd file
cat /tmp/users.tmp | awk 'BEGIN
{FS="|"}{print $1" "$2}' | grep md5 | while read f1 f2
do
echo "setting
passwd of $f1 in /etc/pgpool-II/pool_passwd"
# delete the line
if exits
sed -i -e "/^${f1}:/d"
/etc/pgpool-II/pool_passwd
echo $f1:$f2 >>
/etc/pgpool-II/pool_passwd
done
scp /etc/pgpool-II/pool_passwd
pg02:/etc/pgpool-II/pool_passwd
scp /etc/pgpool-II/pool_passwd
pg03:/etc/pgpool-II/pool_passwd
⚠️ Toda vez que um novo usuário do
postgres é adicionado ou sua senha é alterada, este pequeno procedimento deve
ser executado novamente
3.2. Configurando o arquivo pcp.conf
pcp (protocolo de controle pgpool) é
uma interface administrativa para pgpool, ele permite que você interaja com
pgpool via porta 9898 (padrão). O arquivo pcp.conf armazena um nome de usuário
e uma senha md5 para autenticação, o arquivo .pcppass permite que um usuário
use comandos pcp sem senha. Note que este usuário/senha não está relacionado a
um usuário postgres, é apenas um usuário pcp que pode falar com pgpool via
protocolo pcp. http://www.pgpool.net/docs/latest/en/html/configuring-pcp-conf.html
Vou usar o usuário postgres com senha secreta
# user postgres on pg01
echo "postgres:$(pg_md5 secret)" >>
/etc/pgpool-II/pcp.conf
scp /etc/pgpool-II/pcp.conf
pg02:/etc/pgpool-II/pcp.conf
scp /etc/pgpool-II/pcp.conf
pg03:/etc/pgpool-II/pcp.conf
echo "*:*:postgres:secret" >
/home/postgres/.pcppass
chown postgres:postgres
/home/postgres/.pcppass
chmod 600 /home/postgres/.pcppass
scp /home/postgres/.pcppass
pg02:/home/postgres/.pcppass
scp /home/postgres/.pcppass
pg03:/home/postgres/.pcppass
por causa deste .pcppass poderemos usar o pcp sem senha quando logado
como usuário unix postgres.
No modo watchdog, o pgpool precisará executar os comandos ip e arping
com o usuário postgres, então definimos o sticky bit nesses dois utilitários.
chmod 4755 /usr/sbin/ip /usr/sbin/arping
3.3. Arquivo de configuração do pgpool: pgpool.conf
Os 3 servidores usados na configuração são pg01.localnet,
pg02.localnet e pg03.localnet. Também precisamos de um VIP (IP virtual, também
chamado delegate_ip no contexto do pgpool). No meu caso, o VIP será
192.168.122.50.
Esta é a configuração que eu uso para o primeiro servidor, explicarei
abaixo. Tome cuidado porque, como eu faço um redirecionamento cat para a
configuração, tenho que escapar os cifrões na configuração. Preste atenção ao
if_up_cmd abaixo, por exemplo, escapei o $, mas no arquivo ele não deve ser
escapado.
# as user postgres on pg01
CONFIG_FILE=/etc/pgpool-II/pgpool.conf
cat <<EOF > $CONFIG_FILE
listen_addresses = '*'
port = 9999
socket_dir = '/var/run/pgpool'
pcp_listen_addresses = '*'
pcp_port = 9898
pcp_socket_dir = '/var/run/pgpool'
listen_backlog_multiplier = 2
serialize_accept = off
enable_pool_hba = on
pool_passwd = 'pool_passwd'
authentication_timeout = 60
ssl = off
num_init_children = 100
max_pool = 5
# - Life time -
child_life_time = 300
child_max_connections = 0
connection_life_time = 600
client_idle_limit = 0
log_destination='stderr'
debug_level = 0
pid_file_name =
'/var/run/pgpool/pgpool.pid'
logdir = '/tmp'
connection_cache = on
reset_query_list = 'ABORT; DISCARD ALL'
#reset_query_list = 'ABORT; RESET ALL;
SET SESSION AUTHORIZATION DEFAULT'
replication_mode = off
load_balance_mode = off
master_slave_mode = on
master_slave_sub_mode = 'stream'
backend_hostname0 = 'pg01.localnet'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 =
'/u01/pg11/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_hostname1 = 'pg02.localnet'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 =
'/u01/pg11/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_hostname2 = 'pg03.localnet'
backend_port2 = 5432
backend_weight2 = 1
backend_data_directory2 =
'/u01/pg11/data'
backend_flag2 = 'ALLOW_TO_FAILOVER'
# this is about checking the postgres
streaming replication
sr_check_period = 10
sr_check_user = 'repmgr'
sr_check_password = 'rep123'
sr_check_database = 'repmgr'
delay_threshold = 10000000
# this is about automatic failover
failover_command =
'/opt/pgpool/scripts/failover.sh %d %h
%P %m %H %R'
# not used, just echo something
failback_command = 'echo failback %d %h
%p %D %m %H %M %P'
failover_on_backend_error = 'off'
search_primary_node_timeout = 300
# Mandatory in a 3 nodes set-up
follow_master_command =
'/opt/pgpool/scripts/follow_master.sh %d %h %m %p %H %M %P'
# grace period before triggering a
failover
health_check_period = 40
health_check_timeout = 10
health_check_user = 'hcuser'
health_check_password = 'hcuser'
health_check_database = 'postgres'
health_check_max_retries = 3
health_check_retry_delay = 1
connect_timeout = 10000
#------------------------------------------------------------------------------
# ONLINE RECOVERY
#------------------------------------------------------------------------------
recovery_user = 'repmgr'
recovery_password = 'rep123'
recovery_1st_stage_command =
'pgpool_recovery.sh'
recovery_2nd_stage_command = 'echo
recovery_2nd_stage_command'
recovery_timeout = 90
client_idle_limit_in_recovery = 0
#------------------------------------------------------------------------------
# WATCHDOG
#------------------------------------------------------------------------------
use_watchdog = on
# trusted_servers =
'www.google.com,pg02.localnet,pg03.localnet' (not needed with a 3 nodes cluster
?)
ping_path = '/bin'
wd_hostname = pg01.localnet
wd_port = 9000
wd_priority = 1
wd_authkey = ''
wd_ipc_socket_dir = '/var/run/pgpool'
delegate_IP = '192.168.122.99'
if_cmd_path = '/opt/pgpool/scripts'
if_up_cmd = 'ip_w.sh addr add \$_IP_\$/24 dev eth0 label
eth0:0'
if_down_cmd = 'ip_w.sh addr del \$_IP_\$/24 dev eth0'
arping_path = '/opt/pgpool/scripts'
arping_cmd = 'arping_w.sh -U \$_IP_\$ -I eth0 -w 1'
# - Behaivor on escalation Setting -
heartbeat_destination0 =
'pg01.localnet'
heartbeat_destination_port0 = 9694
heartbeat_destination1 =
'pg02.localnet'
heartbeat_destination_port1 = 9694
heartbeat_destination2 =
'pg03.localnet'
heartbeat_destination_port2 = 9694
other_pgpool_hostname0 =
'pg02.localnet'
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 =
'pg03.localnet'
other_pgpool_port1 = 9999
other_wd_port1 = 9000
EOF
Vamos copiar o arquivo para pg02.localnet e pg03.localnet e fazer as
adaptações necessárias nas seções
scp /etc/pgpool-II/pgpool.conf
pg02.localnet:/etc/pgpool-II/pgpool.conf
em pg02.localnet, mudanças
wd_hostname = pg02.localnet
other_pgpool_hostname0 =
'pg01.localnet'
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 =
'pg03.localnet'
other_pgpool_port1 = 9999
other_wd_port1 = 9000
E o mesmo para pg03.localnet
⚠️ quando há um problema com o watchdog
do pgpool, o motivo geralmente é que a configuração não está correta, por
exemplo, alguém esqueceu de adaptar a seção other_pgpool_hostname em cada nó.
3.4. Alguns parâmetros do pgpool explicados:
parâmetros relacionados à replicação de
streaming.
Prefiro definir load_balance como 'off', mas pode ser um recurso útil em
alguns casos. Ao definir master_slave_mode como on e sub mode como stream,
estamos dizendo ao pgpool que usamos o mecanismo de replicação de streaming
padrão do postgres.
load_balance_mode = off
master_slave_mode = on
master_slave_sub_mode = 'stream'
A seção backend descreve os 3 postgres
backend_hostname0 = 'pg01.localnet'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/u01/pg11/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
etc... for pg02 and pg03
num_init_children e max_pool estão
relacionados à funcionalidade de cache de conexão do pgpool.
Quando o pgpool inicia, ele cria processos clientes “num_init_children”
que estarão todos em um estado “aguardando uma conexão”. Quando um aplicativo
cliente se conecta ao pgpool, o pgpool usa um dos processos filhos que está
livre e estabelece uma conexão com o postgres. Quando o cliente se desconecta,
o pgpool mantém a conexão com o postgres aberta (cache de conexão) para que da
próxima vez que um cliente se conectar ao pgpool, a conexão com o postgres
possa ser reutilizada e evitemos o custo de criar uma nova conexão. Podemos
desabilitar esse cache de conexão se preferirmos ter o pool no nível do
aplicativo.
parâmetros relacionados ao failover
automático
failover_command é o script
que será executado quando o pgpool detectar (por meio do mecanismo de
verificação de integridade no meu caso) que o banco de dados primário está
inativo. Não sei o que o failback_command deve
fazer, eu simplesmente não o uso. O follow_master_command é
executado em todos os nós de espera após o failover_command ter sido executado
e um novo banco de dados primário ter sido detectado. Mostrarei os scripts
correspondentes mais adiante neste documento.
failover_command =
'/opt/pgpool/scripts/failover.sh %d %h
%P %m %H %R'
failback_command = 'echo failback %d %h
%p %D %m %H %M %P'
search_primary_node_timeout = 300
follow_master_command =
'/opt/pgpool/scripts/follow_master.sh %d %h %m %p %H %M %P'
A primeira razão pela qual as pessoas precisam do pgpool é porque o
pgpool pode automatizar o failover e torná-lo transparente para os aplicativos
clientes. Existem basicamente dois mecanismos para disparar um failover. Ou via
failover_on_backend_error ou via health checks. Eu prefiro definir
failover_on_backend_error como off e usar o mecanismo de health check para
disparar o failover. O mecanismo de health check significa que o pgpool se
conectará regularmente ao postgres, se uma conexão falhar (para um primário ou
para um standby), então após o número de tentativas ele disparará o failover.
failover_on_backend_error = 'off'
health_check_period = 40
health_check_timeout = 10
health_check_user = 'hcuser'
health_check_password = 'hcuser'
health_check_database = 'postgres'
health_check_max_retries = 3
health_check_retry_delay = 1
Se você definir failover_on_backend_error como 'on', então o pgpool
acionará o failover quando um dos processos filhos detectar que o postgres foi
encerrado. Nesse caso, não há nova tentativa. Observe também que, nesse caso,
enquanto nenhum aplicativo se conectar ao pgpool ou executar uma consulta no
banco de dados, nenhum failover será acionado.
Não confunda a verificação de integridade com a verificação de replicação
de streaming (a verificação de replicação de streaming verifica o atraso na
replicação, se o atraso for muito grande, um standby não será usado para
balanceamento de carga de leitura e não será considerado para promoção). Por
alguma razão estranha, o pgpool usa dois usuários diferentes para isso.
parâmetros relacionados ao watch-dog
O mecanismo watch-dog é uma funcionalidade muito legal do pgpool:
múltiplas instâncias do pgpool (3 no nosso caso) estão em uma configuração
ativa-passiva, na inicialização o cluster elege um líder e o líder adquire o
VIP (delegate_ip). Os 3 nós estão monitorando um ao outro e se o primário
falhar, então um novo líder será eleito e o VIP será movido para este novo
líder.
Somente o nó líder pgpool executará os comandos failover, follow_master,
etc.
O modo watchdog deve ser habilitado via use_watchdog ('on')
Os nós monitoram uns aos outros por meio do mecanismo de pulsação,
enviando um pacote na porta UDP 9694 para os outros nós
heartbeat_destination0 =
'pg01.localnet'
heartbeat_destination_port0 = 9694
heartbeat_destination1 =
'pg02.localnet'
heartbeat_destination_port1 = 9694
heartbeat_destination2 =
'pg03.localnet'
heartbeat_destination_port2 = 9694
O VIP é adquirido por meio de um script que deve ser instalado no host.
if_cmd_path = '/opt/pgpool/scripts'
if_up_cmd = 'ip_w.sh addr add $_IP_$/24
dev eth0 label eth0:0'
if_down_cmd = 'ip_w.sh addr del
$_IP_$/24 dev eth0'
arping_path = '/opt/pgpool/scripts'
arping_cmd = 'arping_w.sh -U $_IP_$ -I
eth0 -w 1'
No comando acima, o pgpool
substituirá $ IP $ pelo valor do parâmetro
delegate_ip
delegate_ip = 192.168.122.99
cada nó deve estar ciente dos outros, então em pg01
wd_hostname = pg01
wd_port = 9000
wd_priority = 1
wd_authkey = ''
wd_ipc_socket_dir = '/var/run/pgpool'
other_pgpool_hostname0 =
'pg02.localnet'
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 =
'pg03.localnet'
other_pgpool_port1 = 9999
other_wd_port1 = 9000
destino do log
Eu uso o log_destination padrão = 'stderr' e olho os logs via journalctl
sudo journalctl --unit pgpool
3.5. preparação do pgpool
precisamos criar o usuário postgres para a verificação de integridade
# on pg01 as user postgres
psql -c "create user hcuser with login
password 'hcuser';"
Precisamos abrir algumas portas de firewall, para pgpool (9999 e 9898
para pcp) e para a funcionalidade watch-dog
# on all 3 servers
# port for postgres (was already done)
sudo firewall-cmd --add-port 9898/tcp --permanent
# ports for pgpool and for pcp
sudo firewall-cmd --add-port 9898/tcp --permanent
sudo firewall-cmd --add-port 9999/tcp --permanent
sudo firewall-cmd --add-port 9000/tcp --permanent
sudo firewall-cmd --add-port 9694/udp --permanent
sudo systemctl restart firewalld
Diretório para arquivo pid
# on all servers
sudo chown postgres:postgres
/var/run/pgpool
sudo mkdir /var/log/pgpool
sudo chown postgres:postgres
/var/log/pgpool
Os scripts pgpool farão login em /var/log/pgpool.
Se você quiser também logs do próprio pgpool, então use as
log_destination = 'stderr,syslog' e defina syslog_facility para LOCAL1, e
configure syslog. Adicione a /etc/rsyslog.conf
local1.* /var/log/pgpool/pgpool.log
então reinicie o daemon
sudo systemctl restart rsyslog
Nota: não tenho certeza se isso está funcionando, não testei.
3.5. Scripts do Pgpool
sudo mkdir -p
/opt/pgpool/scripts
sudo chown postgres:postgres
/opt/pgpool/scripts
script de failover
Copie e cole o seguinte em /opt/pgpoo/scripts/failover.sh
#!/bin/bash
LOGFILE=/var/log/pgpool/failover.log
if [ ! -f $LOGFILE ] ; then
> $LOGFILE
fi
# we need this, otherwise it is not set
PGVER=${PGVER:-11}
#
#failover_command =
'/scripts/failover.sh %d %h %P %m %H %R'
# Executes this command at failover
# Special values:
# %d = node id
# %h =
host name
# %p = port number
# %D = database cluster path
# %m = new master node id
# %H = hostname of the new master node
# %M = old master node id
# %P = old primary node id
#
FALLING_NODE=$1 # %d
FALLING_HOST=$2 # %h
OLD_PRIMARY_ID=$3 # %P
NEW_PRIMARY_ID=$4 # %m
NEW_PRIMARY_HOST=$5 # %H
NEW_MASTER_PGDATA=$6 # %R
(
date
echo "FALLING_NODE: $FALLING_NODE"
echo "FALLING_HOST: $FALLING_HOST"
echo "OLD_PRIMARY_ID: $OLD_PRIMARY_ID"
echo "NEW_PRIMARY_ID: $NEW_PRIMARY_ID"
echo "NEW_PRIMARY_HOST: $NEW_PRIMARY_HOST"
echo "NEW_MASTER_PGDATA: $NEW_MASTER_PGDATA"
ssh_options="ssh -p 22 -n
-T -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
set -x
if [ $FALLING_NODE = $OLD_PRIMARY_ID ] ; then
$ssh_options postgres@${NEW_PRIMARY_HOST} "/usr/pgsql-${PGVER}/bin/repmgr
--log-to-file -f /etc/repmgr/${PGVER}/repmgr.conf standby promote -v "
fi
exit 0;
torná-lo executável
seguir_mestre
Copie o seguinte em /opt/pgpool/scripts/follow_master.sh
#!/bin/bash
LOGFILE=/var/log/pgpool/follow_master.log
if [ ! -f $LOGFILE ] ; then
> $LOGFILE
fi
PGVER=${PGVER:-11}
echo "executing follow_master.sh at `date`" | tee -a $LOGFILE
NODEID=$1
HOSTNAME=$2
NEW_MASTER_ID=$3
PORT_NUMBER=$4
NEW_MASTER_HOST=$5
OLD_MASTER_ID=$6
OLD_PRIMARY_ID=$7
PGDATA=${PGDATA:-/u01/pg${PGVER}/data}
(
echo NODEID=${NODEID}
echo HOSTNAME=${HOSTNAME}
echo NEW_MASTER_ID=${NEW_MASTER_ID}
echo PORT_NUMBER=${PORT_NUMBER}
echo NEW_MASTER_HOST=${NEW_MASTER_HOST}
echo OLD_MASTER_ID=${OLD_MASTER_ID}
echo OLD_PRIMARY_ID=${OLD_PRIMARY_ID}
echo PGDATA=${PGDATA}
if [ $NODEID -eq $OLD_PRIMARY_ID ] ; then
echo "Do nothing as
this is the failed master. We could prevent failed master to restart here, so
that we can investigate the issue" | tee -a $LOGFILE
else
ssh_options="ssh -p 22 -n
-T -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
set -x
# if
this node is not currently standby then it might be an old master that went
back up after a failover occured
# if
this is the case we cannot do the follow master command on this node, we should
leave it alone
in_reco=$( $ssh_options postgres@${HOSTNAME} 'psql -t -c
"select pg_is_in_recovery();"' | head -1 | awk '{print $1}' )
echo "pg_is_in_recovery
on $HOSTNAME is $in_reco " | tee -a $LOGFILE
if [ "a${in_reco}" != "at" ] ; then
echo "node $HOSTNAME is not in
recovery, probably a degenerated master, skip it" | tee -a $LOGFILE
exit
0
fi
$ssh_options postgres@${HOSTNAME} "/usr/pgsql-${PGVER}/bin/repmgr
--log-to-file -f /etc/repmgr/${PGVER}/repmgr.conf -h ${NEW_MASTER_HOST} -D ${PGDATA} -U repmgr -d
repmgr standby follow -v "
#
TODO: we should check if the standby follow worked or not, if not we should
then do a standby clone command
echo "Sleep
10"
sleep
10
echo "Attach node ${NODEID}"
pcp_attach_node -h localhost -p 9898 -w ${NODEID}
fi
) 2>&1 | tee -a $LOGFILE
script pgpool_recovery
o script pgpool_recovery.sh deve ser instalado em $PGDATA, deve ser de
propriedade do postgres e ter permissão de execução. Este script será chamado
via extensão pgpool_recovery do postgres, então precisamos primeiro instalar
esta extensão.
# on the primary db only
psql -c "create extension
pgpool_recovery;" -d template1
psql -c "create extension
pgpool_adm;"
pgpool_adm é outra extensão que você pode querer instalar
crie o arquivo $PGDATA/pgpool_recovery.sh (no meu caso $PGDATA é
/u01/pg11/data). Eu também instalo esse script em /opt/pgpool/scripts. para
manter uma cópia.
#!/bin/bash
# This script erase an existing replica
and re-base it based on
# the current primary node. Parameters
are position-based and include:
#
# 1 - Path to primary database
directory.
# 2 - Host name of new node.
# 3 - Path to replica database
directory
#
# Be sure to set up public SSH keys and
authorized_keys files.
# this script must be in PGDATA
PGVER=${PGVER:-11}
ARCHIVE_DIR=/u02/archive
LOGFILE=/var/log/pgool/pgpool_recovery.log
if [ ! -f $LOGFILE ] ; then
touch $LOGFILE
fi
log_info(){
echo $( date +"%Y-%m-%d
%H:%M:%S.%6N" ) - INFO - $1 | tee -a $LOGFILE
}
log_error(){
echo $( date +"%Y-%m-%d
%H:%M:%S.%6N" ) - ERROR - $1 | tee -a $LOGFILE
}
log_info "executing pgpool_recovery at `date` on `hostname`"
PATH=$PATH:/usr/pgsql-${PGVER}/bin
if [ $# -lt 3 ]; then
echo "Create a
replica PostgreSQL from the primary within pgpool."
echo
echo "Usage: $0 PRIMARY_PATH
HOST_NAME COPY_PATH"
echo
exit 1
fi
# to do is hostname -i always OK ? Find
other way to extract the host. maybe from repmgr.conf ?
primary_host=$(hostname -i) # not working on
SCM
replica_host=$2
replica_path=$3
log_info "primary_host: ${primary_host}"
log_info "replica_host: ${replica_host}"
log_info "replica_path: ${replica_path}"
ssh_copy="ssh -p 22 postgres@$replica_host -T -n -o
UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
log_info "Stopping postgres on ${replica_host}"
$ssh_copy "sudo systemctl stop
postgresql"
log_info sleeping 10
sleep 10
log_info "delete database directory on ${replica_host}"
$ssh_copy "rm -Rf $replica_path/* $ARCHIVE_DIR/*"
log_info "let us use repmgr on the replica
host to force it to sync again"
$ssh_copy "/usr/pgsql-${PGVER}/bin/repmgr -h ${primary_host} --username=repmgr
-d repmgr -D ${replica_path} -f /etc/repmgr/${PGVER}/repmgr.conf
standby clone -v"
log_info "Start database on ${replica_host} "
$ssh_copy "sudo systemctl start
postgresql"
log_info sleeping 20
sleep 20
log_info "Register standby database"
$ssh_copy "/usr/pgsql-${PGVER}/bin/repmgr -f
/etc/repmgr/${PGVER}/repmgr.conf
standby register -F -v"
Não se esqueça de instalá-lo em $PGDATA e definir a permissão de
execução
chmod 774
/opt/pgpool/scripts/pgpool_recovery.sh
cp /opt/pgpool/scripts/pgpool_recovery.sh
$PGDATA/pgpool_recovery.sh
scp
/opt/pgpool/scripts/pgpool_recovery.sh pg02.localnet:$PGDATA/
scp
/opt/pgpool/scripts/pgpool_recovery.sh pg03.localnet:$PGDATA/
para o modo watchdog, precisamos de dois scripts adicionais
scripts ip
Crie o arquivo /opt/pgool/scripts/ip_w.sh
#!/bin/bash
echo "Exec ip with params $@ at `date`"
sudo /usr/sbin/ip $@
exit $?
Crie o arquivo /opt/pgpool/scripts/arping_w.sh
#!/bin/bash
echo "Exec arping with params $@ at `date`"
sudo /usr/sbin/arping $@
exit $?
Agora defina o modo de execução em todos os scripts e copie-os para pg02
e pg03
chmod 774 /opt/pgpool/scripts/*
scp /opt/pgpool/scripts/*
pg02.localnet:/opt/pgpool/scripts/
scp /opt/pgpool/scripts/*
pg03.localnet:/opt/pgpool/scripts/
4. Teste a configuração
Antes de iniciar o pgpool nos nós pg01.localnet, pg02.localnet e
pg03.localnet, vamos fazer as verificações finais
verificar replicação de streaming
# on pg01
repmgr -f /etc/repmgr/11/repmgr.conf cluster
show
habilitar serviços postgressql e
pgpool em todos os servidores
sudo systemctl enable postgresql
sudo systemctl enable pgpool
verifique o firewall em todos os
servidores
sudo firewall-cmd --list-all
verifique a conectividade ssh entre
todos os servidores
lembre-se de que o pg01 também se conectará a si mesmo via ssh, e o
pg02/3 também
inicie o pgpool em pg01.localnet, pg02.localnet e pg03.localnet
sudo systemctl start pgpool
assim que houver quorum (dois nós), o pgpool elegerá um líder e
adquirirá o VIP
Como o pgpool está registrando no stderr, podemos ver os logs com journalctl
sudo journalctl --unit pgpool -f
Dê uma boa olhada nos logs, eles são um pouco prolixos, mas muito
relevantes. Depois de iniciar o pgpool em pg02.localnet e pg03.localnet, você
deve ver no log que um master foi eleito e que o VIP foi adquirido. O VIP
estará no nó master, no meu caso pg01.localnet (ele começou primeiro)
obter informações sobre o cluster pgpool
pcp_watchdog_info -h 192.168.122.99 -p 9898 -w -v
o sinalizador -w é para evitar solicitação de senha, ele requer ter a
senha pcp para postgres em /home/postgres/.pcppass (a senha md5 é definida em
/etc/pgpool-II/pcp.conf)
# result of ip addr
[postgres@pg01 pgpool-II]$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu
65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0:
<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP
group default qlen 1000
link/ether 52:54:00:b5:58:ec brd ff:ff:ff:ff:ff:ff
inet 192.168.122.10/24 brd 192.168.122.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.122.99/24 scope global secondary eth0:0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:feb5:58ec/64 scope link
valid_lft forever preferred_lft forever
a informação importante é que o IP 192.168.122.99 foi configurado no
eth0 com o rótulo eth0:0
4.1. failover pgpool
antes de testar o failover, certifique-se de que todos os nós podem se
conectar uns aos outros via ssh sem um prompt de senha
# on pg01, pg02 and pg03
ssh -p 22 postgres@pg01.localnet -T -n -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no "repmgr -f
/etc/repmgr/${PGVER}/repmgr.conf
--help"
ssh -p 22 postgres@pg02.localnet -T -n -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no "repmgr -f
/etc/repmgr/${PGVER}/repmgr.conf
--help"
ssh -p 22 postgres@pg03.localnet -T -n -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no "repmgr -f
/etc/repmgr/${PGVER}/repmgr.conf
--help"
para testar um failover do pgpool precisamos parar o pgpool no master e
ver se um novo master é eleito e se o VIP é movido para o novo master. Siga os
logs durante essa operação porque ele fornece todas as informações relevantes.
sudo systemctl stop pgpool
Verifique se o VIP foi movido.
reiniciar pgpool
sudo systemctl start pgpool
4.2. failover postgres
Vamos ver o estado do pgpool
psql -h 192.168.122.99 -p 9999 -U repmgr -c "show
pool_nodes;"
vamos ver também as estatísticas de replicação no primário e no standby
# pg01 is the primary
psql -h pg01.localnet -p 5432 -U repmgr -c "select * from
pg_stat_replication;"
psql -h pg02.localnet -p 5432 -U repmgr -c "select * from
pg_stat_wal_receiver;"
psql -h pg03.localnet -p 5432 -U repmgr -c "select * from
pg_stat_wal_receiver;"
como pg01.localnet é o primário, vou interrompê-lo e o pgpool deve
promover o pg02 para primário (script de failover) e o pg03 deve agora seguir o
novo primário.
# on pg01
sudo systemctl stop postgresql
Verifique novamente o status do pgpool
psql -h 192.168.122.99 -p 9999 -U repmgr -c "show
pool_nodes;"
verifique os arquivos de log failover.log e follow_master.log em
/var/log/pgool no nó mestre pgpool
verifique com select * from pg_stat_wal_receiver; que o segundo stand-by
segue o novo primário e verifique com select * from pg_stat_replication; que o
primário transmite para o standby
4.3. recuperar nó com falha
Existem diferentes maneiras de rebasear o primário com falha como um
standby
usando repmgr
assumindo que o novo primário é pg02.localnet, executando o seguinte
para que pg01.localnet se junte novamente ao cluster como um standby. Observe
que nem sempre funcionará
repmgr node rejoin -d 'host=pg02.localnet
dbname=repmgr user=repmgr password=rep123 connect_timeout=2'
e então reconecte o nó ao pgpool
pcp_attach_node -h 192.168.122.99 -p 9898 -w 0
Mas a maneira mais segura é reconstruí-lo, usando pcp_recovery_node. O
pgpool usará os parâmetros recovery_user e recovery_password para conectar-se
ao banco de dados e executar “select pg_recovery(…)”. A função pgpool_recovery
foi criada quando instalamos a extensão pgpool.
No nosso caso tivemos
recovery_user = 'repmgr'
recovery_password = 'rep123'
pcp_recovery_node -h 192.168.122.99 -p 9898 -w 0
e então reconecte o nó
pcp_attach_node -h 192.168.122.99 -p 9898 -w 0
4.4. Recuperação automática de um mestre ou standby com falha
Na minha empresa, eles queriam que um master com falha (ou um standby
com falha) que voltasse à vida fosse automaticamente colocado de volta no
cluster como um standby. Por exemplo, supondo este cenário:
pg01 é o primário
o servidor pg01 está desligado
pg02 se torna o primário, pg03 segue pg02
o servidor pg01 está ligado
postgres no pg01 retorna, está em modo de leitura e gravação, porém como está
separado do pgpool estamos protegidos de um split-brain
queremos que o pg01 seja recuperado automaticamente e se torne um
standby do pg02 e se junte novamente ao cluster pgpool
Outro cenário é quando um servidor em espera é reinicializado: o pgpool
desanexará o banco de dados em espera, mas quando o servidor retornar, o pgpool
não o reconectará.
Minha solução foi agendar um script via cron. O script é o seguinte.
Tome cuidado para que ele seja adaptado no pg02 e no pg03, a variável
PG_NODE_ID é 0 no pg01, 1 no pg02 e 2 no pg03. Adapte também a var DELEGATE_IP
(192.168.122.99 para mim)
# content of
/opt/postgres/scripts/recover_failed_node.sh (can be scheduled via cron)
#!/bin/bash
# this script will re-attach a failed
standby database
# or recover a failed primary database
# it requires that pgpool is available
and that the database on this node is running
# this script might be called when the
postgres container is starting but then it must do so
# when both pgpool and the database is
running. Since the db is started with supervisor, this would
# require to lauch the script in the
background after the start of postgres
# the script can also be started
manually or via cron
# Created by argbash-init v2.6.1
#
ARG_OPTIONAL_BOOLEAN([auto-recover-standby],[],[reattach a standby to pgpool if
possible],[on])
#
ARG_OPTIONAL_BOOLEAN([auto-recover-primary],[],[recover the degenerated
master],[off])
#
ARG_OPTIONAL_SINGLE([lock-timeout-minutes],[],[minutes after which a lock will
be ignored (optional)],[120])
# ARG_HELP([<The general help
message of my script>])
# ARGBASH_GO()
# needed because of Argbash -->
m4_ignore([
### START OF CODE GENERATED BY Argbash
v2.6.1 one line above ###
# Argbash is a bash code generator used
to get arguments parsing right.
# Argbash is FREE SOFTWARE, see
https://argbash.io for more info
die()
{
local _ret=$2
test -n "$_ret" || _ret=1
test "$_PRINT_HELP" = yes && print_help >&2
echo "$1" >&2
exit ${_ret}
}
begins_with_short_option()
{
local first_option
all_short_options
all_short_options='h'
first_option="${1:0:1}"
test "$all_short_options" = "${all_short_options/$first_option/}" && return 1 || return 0
}
# THE DEFAULTS INITIALIZATION -
OPTIONALS
_arg_auto_recover_standby="on"
_arg_auto_recover_primary="off"
_arg_lock_timeout_minutes="120"
print_help ()
{
printf '%s\n' "<The
general help message of my script>"
printf 'Usage: %s
[--(no-)auto-recover-standby] [--(no-)auto-recover-primary]
[--lock-timeout-minutes <arg>] [-h|--help]\n' "$0"
printf '\t%s\n' "--auto-recover-standby,--no-auto-recover-standby:
reattach a standby to pgpool if possible (on by default)"
printf '\t%s\n' "--auto-recover-primary,--no-auto-recover-primary:
recover the degenerated master (off by default)"
printf '\t%s\n' "--lock-timeout-minutes:
minutes after which a lock will be ignored (optional) (default: '120')"
printf '\t%s\n' "-h,--help:
Prints help"
}
parse_commandline ()
{
while test $# -gt 0
do
_key="$1"
case "$_key" in
--no-auto-recover-standby|--auto-recover-standby)
_arg_auto_recover_standby="on"
test "${1:0:5}" = "--no-" && _arg_auto_recover_standby="off"
;;
--no-auto-recover-primary|--auto-recover-primary)
_arg_auto_recover_primary="on"
test "${1:0:5}" = "--no-" && _arg_auto_recover_primary="off"
;;
--lock-timeout-minutes)
test $# -lt 2 && die "Missing value
for the optional argument '$_key'." 1
_arg_lock_timeout_minutes="$2"
shift
;;
--lock-timeout-minutes=*)
_arg_lock_timeout_minutes="${_key##--lock-timeout-minutes=}"
;;
-h|--help)
print_help
exit 0
;;
-h*)
print_help
exit 0
;;
*)
_PRINT_HELP=yes die "FATAL ERROR:
Got an unexpected argument '$1'" 1
;;
esac
shift
done
}
parse_commandline "$@"
# OTHER STUFF GENERATED BY Argbash
### END OF CODE GENERATED BY Argbash
(sortof) ### ])
# [ <-- needed because of Argbash
printf "'%s' is %s\\n" 'auto-recover-standby' "$_arg_auto_recover_standby"
printf "'%s' is %s\\n" 'auto-recover-primary' "$_arg_auto_recover_primary"
printf "'%s' is %s\\n" 'lock-timeout-minutes' "$_arg_lock_timeout_minutes"
PIDFILE=/home/postgres/recover_failed_node.pid
trap cleanup EXIT
DELEGATE_IP=192.168.122.99
### adapt on each node ###
PGP_NODE_ID=0
PGP_STATUS_WAITING=1
PGP_STATUS_UP=2
PGP_STATUS_DOWN=3
LOGFILENAME="${PROGNAME%.*}.log"
LOGFILE=/var/log/postgres/${LOGFILENAME}
if [ ! -f $LOGFILE ] ; then
touch $LOGFILE
fi
log_info(){
echo $( date +"%Y-%m-%d
%H:%M:%S.%6N" ) - INFO - $1 | tee -a $LOGFILE
}
log_error(){
echo $( date +"%Y-%m-%d
%H:%M:%S.%6N" ) - ERROR - $1 | tee -a $LOGFILE
}
cleanup(){
#
remove pid file but only if it is mine, dont remove if another process was
running
if [ -f $PIDFILE ] ; then
MYPID=$$
STOREDPID=$(cat $PIDFILE)
if [ "${MYPID}" == "${STOREDPID}" ] ; then
rm -f $PIDFILE
fi
fi
if [ -z $INSERTED_ID ] ; then
return
fi
log_info
"delete
from recover_failed with id $INSERTED_ID"
psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -t -c "delete from
recover_failed_lock where id=${INSERTED_ID};"
}
# test if there is lock in the
recover_failed_lock table
# return 0 if there is no lock, 1 if
there is one
is_recovery_locked(){
#
create table if not exists
psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -c "create table
if not exists recover_failed_lock(id serial,ts timestamp with time zone default
current_timestamp,node varchar(10) not null,message varchar(120));"
#clean-up
old records
psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -c "delete from
recover_failed_lock where ts < current_timestamp - INTERVAL '1 day';"
#
check if there is already an operation in progress
str=$(psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -c "select
ts,node from recover_failed_lock where ts > current_timestamp - INTERVAL '${_arg_lock_timeout_minutes} min';")
if [ $? -ne 0 ] ; then
log_error
"psql
error when selecting from recover_failed_lock table"
exit
1
fi
echo $str | grep "(0
rows)"
if [ $? -eq 0 ] ; then
return 0
fi
log_info
"there
is a lock record in recover_failed_lock : $str"
return
1
}
# take a lock on the the recovery
operation
# by inserting a record in table
recover_failed_lock
# fails if there is already a recovery
running (if an old record still exist)
# exit -1 : error
#
return 0: cannot acquire a lock because an operation is already in
progress
lock_recovery(){
MSG=$1
#
create table if not exists
psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -c "create table
if not exists recover_failed_lock(id serial,ts timestamp with time zone default
current_timestamp,node varchar(10) not null,message varchar(120));"
if [ $? -ne 0 ] ; then
log_error
"Cannot
create table recover_failed_lock table"
exit
1
fi
is_recovery_locked
if [ $? -eq 1 ] ; then
return 0
fi
str=$(psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -t -c "insert into
recover_failed_lock (node,message) values ('${NODE_NAME}','${MSG}') returning id;")
if [ $? -ne 0 ] ; then
log_info
"cannot
insert into recover_failed_lock"
exit
1
fi
INSERTED_ID=$(echo $str | awk '{print $1}')
log_info "inserted
lock in recover_failed_log with id $INSERTED_ID"
return $INSERTED_ID
}
pg_is_in_recovery(){
psql -t -c "select
pg_is_in_recovery();" | head -1 | awk '{print $1}'
}
check_is_streaming_from(){
PRIMARY=$1
#
first check if is_pg_in_recovery is t
in_reco=$( pg_is_in_recovery )
if [ "a${in_reco}" != "at" ] ; then
return 0
fi
psql
-t -c "select * from
pg_stat_wal_receiver;" > /tmp/stat_wal_receiver.tmp
#
check that status is streamin
status=$( cat
/tmp/stat_wal_receiver.tmp | head -1 | cut -f2 -d"|" | sed -e "s/ //g" )
if [ "a${status}" != "astreaming" ] ; then
log_info
"status
is not streaming"
return
0
fi
#check
that is recovering from primary
conninfo=$( cat
/tmp/stat_wal_receiver.tmp | head -1 | cut -f14 -d"|" )
echo $conninfo | grep "host=${PRIMARY}"
if [ $? -eq 1 ] ; then
log_info
"not
streaming from $PRIMARY"
return
0
fi
return 1
}
# arg: 1 message
recover_failed_master(){
#
try to acquire a lock
MSG=$1
lock_recovery "$MSG"
LOCK_ID=$?
if [ ${LOCK_ID} -eq 0 ] ; then
log_info
"cannot
acquire a lock, probably an old operation is in progress ?"
return
99
fi
log_info
"acquired
lock $LOCK_ID"
#echo
"First try node rejoin"
#echo
"todo"
log_info "Do
pcp_recovery_node of $PGP_NODE_ID"
pcp_recovery_node -h $DELEGATE_IP -p 9898 -w $PGP_NODE_ID
ret=$?
cleanup
return $ret
}
recover_standby(){
#dont
do it if there is a lock on recover_failed_lock
is_recovery_locked
if [ $? -eq 1 ] ; then
return 0
fi
if [ "$_arg_auto_recover_standby" == "on" ] ; then
log_info
"attach
node back since it is in recovery streaming from $PRIMARY_NODE_ID"
pcp_attach_node -h $DELEGATE_IP -p 9898 -w ${PGP_NODE_ID}
if [ $? -eq 0 ] ; then
log_info
"OK
attached node $node back since it is
in recovery and streaming from $PRIMARY_NODE_ID"
exit
0
fi
log_error
"attach
node failed for node $node"
exit
1
else
log_info
"auto_recover_standby
is off, do nothing"
exit
0
fi
}
if [ -f $PIDFILE ] ; then
PID=$(cat $PIDFILE)
ps -p $PID > /dev/null
2>&1
if [ $? -eq 0 ] ; then
log_info
"script
already running with PID $PID"
exit
0
else
log_info
"PID
file is there but script is not running, clean-up $PIDFILE"
rm -f $PIDFILE
fi
fi
echo $$ > $PIDFILE
if [ $? -ne 0 ] ; then
log_error
"Could
not create PID file"
exit
1
fi
log_info "Create $PIDFILE with value $$"
str=$( pcp_node_info -h $DELEGATE_IP -p 9898 -w $PGP_NODE_ID )
if [ $? -ne 0 ] ; then
log_error
"pgpool
cannot be accessed"
rm -f $PIDFILE
exit
1
fi
read node port status weight status_name
role date_status time_status <<< $str
if [ $status -ne $PGP_STATUS_DOWN ] ; then
log_info
"pgpool
status for node $node is $status_name and role $role, nothing to
do"
rm -f $PIDFILE
exit
0
fi
log_info "Node $node is down (role is $role)"
# status down, the node is detached
# get the primary from pool_nodes
psql -h $DELEGATE_IP -p 9999 -U repmgr -c "show pool_nodes;" >
/tmp/pool_nodes.log
if [ $? -ne 0 ] ; then
log_error
"cannot
connect to postgres via pgpool"
rm -f $PIDFILE
exit
1
fi
PRIMARY_NODE_ID=$( cat
/tmp/pool_nodes.log | grep
primary
| grep -v down | cut -f1 -d"|" | sed -e "s/ //g")
PRIMARY_HOST=$( cat
/tmp/pool_nodes.log | grep
primary
| grep -v down | cut -f2 -d"|" | sed -e "s/ //g")
log_info "Primary node is $PRIMARY_HOST"
# check if this node is a failed master
(degenerated master)
# if yes then pcp_recovery_node or node
rejoin is needed
if [ $role == "primary" ] ; then
#
this should never happen !!
log_info "This
node is a primary and it is down: recovery needed"
#
sanity check
if [ $PRIMARY_NODE_ID -ne $PGP_NODE_ID ] ; then
log_error
"Unpextected
state, this node $PGP_NODE_ID is a primary
according to pcp_node_info but pool_nodes said $PRIMARY_NODE_ID is master"
rm -f $PIDFILE
exit
1
fi
if [ "$_arg_auto_recover_primary" == "on" ] ; then
recover_failed_master
"primary
node reported as down in pgpool"
ret=$?
rm -f $PIDFILE
exit $ret
else
log_info
"auto_recover_primary
is off, do nothing"
rm -f $PIDFILE
exit
0
fi
fi
log_info "This node is a standby and it is
down: check if it can be re-attached"
log_info "Check if the DB is running, if
not do not start it but exit with error"
pg_ctl status
if [ $? -ne 0 ] ; then
log_error
"the
DB is not running"
rm -f $PIDFILE
exit
1
fi
check_is_streaming_from $PRIMARY_HOST
res=$?
if [ $res -eq 1 ] ; then
recover_standby
ret=$?
rm -f $PIDFILE
exit $ret
fi
if [ "$_arg_auto_recover_primary" == "on" ] ; then
log_info
"node
is standby in pgpool but it is not streaming from the primary, probably a
degenerated master. Lets do pcp_recovery_node"
recover_failed_master "standby node not streaming from the
primary"
ret=$?
rm -f $PIDFILE
exit $ret
else
log_info
"node
is supposed to be a standby but it is not streaming from the primary, however
auto_recovery_primary is off so do nothing"
fi
rm -f $PIDFILE
exit 0
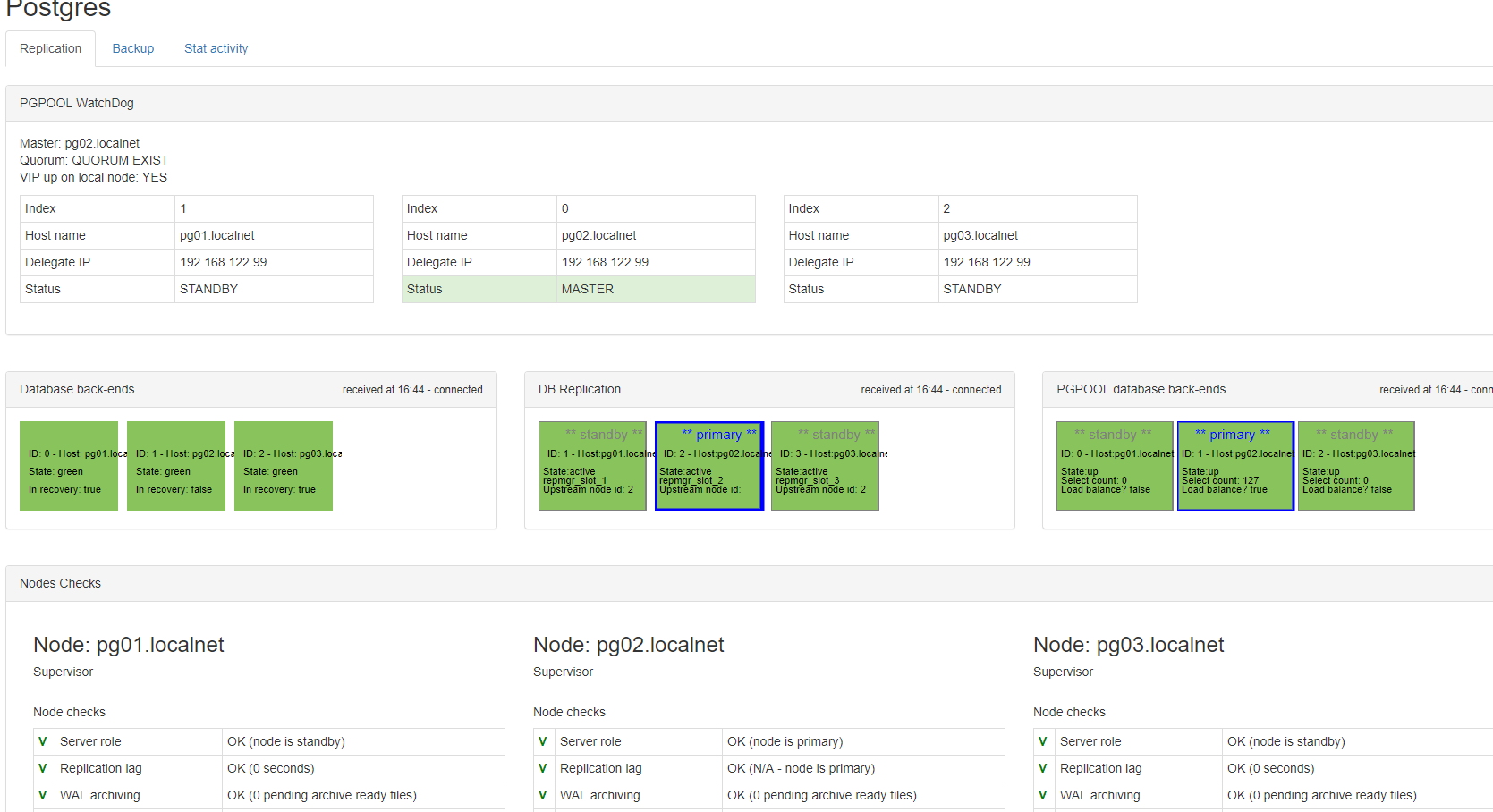
interface gráfica pgpool
Desenvolvi uma aplicação baseada na web em cima do pgpool e postgres
para visualizar o cluster (estado do watchdog e estado da replicação). Por
enquanto, a maneira mais fácil de usá-lo é clonar o repositório do github,
construir uma imagem docker contendo o aplicativo e então executar a imagem
docker em um dos nós ou em outro servidor (ele precisa de acesso aos servidores
posgres via ssh)
Vou passar pelo processo de construir
a imagem do docker e iniciá-la no meu host. Observe que, dependendo de como
você instala o docker (do docker-ce ou do centos), pode ser necessário usar o
sudo para executar comandos do docker como usuário não root. Observe que ele
requer uma versão do docker que suporte construção em vários estágios, então vá
para docker-ce https://docs.docker.com/install/linux/docker-ce/centos/
# clone the github project
git clone
git@github.com:saule1508/pgcluster.git
# get into the directory containing the
app
cd pgcluster/manager
# get into the build directory
cd build
#
NB: the user must be in the group docker, otherwise you need to add a
sudo in front of the docker commands
#
in the script build.bash
./build.bash
No final do script, uma imagem docker deve ser criada, ela deve dizer
“Gerente marcado com sucesso:"no meu caso é manager:0.8.0
O contêiner precisa de uma variável de ambiente PG_BACKEND_NODE_LIST que
é uma lista csv dos backends. Ele também precisa da senha do usuário repmgr.
Então, neste caso:
PG_BACKEND_NODE_LIST: 0:pg01.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER,1:pg02.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER,2:pg03.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER
REPMGRPWD: rep123
o contêiner docker também deve ser capaz de se conectar aos 3 nós do
postgres via ssh, sem uma senha: para tornar isso possível, precisaremos copiar
a chave pública armazenada na imagem para os 3 servidores (a chave pública deve
ser adicionada a /root/.ssh/authorized_keys nos backends, podemos usar
ssh-copy-id para isso)
inicie o contêiner para copiar a chave pública
docker run -ti --net host --entrypoint
bash manager:0.8.0
# now we are inside the container,
check that you can ping the backends
ping pg01.localnet
ping pg02.localnet
ping pg03.localnet
# copy the public key
ssh-copy-id postgres@pg01.localnet
ssh-copy-id postgres@pg02.localnet
ssh-copy-id postgres@pg03.localnet
# exit the container
exit
A ferramenta executa um script chamado /opt/postgres/scripts/checks.sh
no backend, então devemos instalá-lo nos 3 servidores
#!/bin/bash
repmgr node check | grep -v "^Node" | while read line
do
ck=$(echo $line | sed -e "s/\t//" -e "s/ /_/g" | cut -f1 -d":")
res=$(echo $line | cut -f2- -d":")
echo
repmgr,$ck,$res
done
df -k ${PGDATA} | grep -v "^Filesystem" | awk '{print
"disk,"$NF","$5","$2","$3}'
df -k /backup | grep -v "^Filesystem" | awk '{print
"disk,"$NF","$5","$2","$3}'
df -k /archive | grep -v "^Filesystem" | awk '{print
"disk,"$NF","$5","$2","$3}'
E agora podemos executar o container. Ele vai expor a porta 8080, então
precisamos abrir essa porta no firewall
firewall-cmd --add-port 8080/tcp
--permanent
systemctl restart firewalld
systemctl restart docker
docker run -d --net host \
-v
/var/run/docker.sock:/var/run/docker.sock \
-e PG_BACKEND_NODE_LIST=0:pg01.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER,1:pg02.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER,2:pg03.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER
\
-e REPMGRPWD:rep123 \
-e DBHOST=192.168.122.99 \
-e SCRIPTSDIR=/opt/postgres/scripts
-e SSHPORT=22 -e BACKUPDIR=/u02/backup \
--name pgpoolmanager
manager:0.8.0
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-3131118931911114"
crossorigin="anonymous"></script>
Nenhum comentário:
Postar um comentário